Natural Language Basics with TextBlob
In this chapter, we’ll use a Python library called TextBlob to perform simple natural language processing tasks.
“Natural Language Processing” is a field at the intersection of computer science, linguistics and artificial intelligence which aims to make the underlying structure of language available to computer programs for analysis and manipulation. It’s a vast and vibrant field with a long history! New research and techniques are being developed constantly.
The aim of this chapter is to introduce a few simple concepts and techniques from NLP—just the stuff that’ll help you do creative things quickly, and maybe open the door for you to understand more sophisticated NLP concepts that you might encounter elsewhere.
The most commonly known library for doing NLP in Python is NLTK. NLTK is a fantastic library, but it’s also a writhing behemoth: large and slippery and difficult to understand. TextBlob is a simpler, more humane interface to much of NLTK’s functionality: perfect for NLP beginners or poets that just want to get work done.
Natural language
“Natural language” is a loaded phrase: what makes one stretch of language “natural” while another stretch is not? NLP techniques are opinionated about what language is and how it works; as a consequence, you’ll sometimes find yourself having to conceptualize your text with uncomfortable abstractions in order to make it work with NLP. (This is especially true of poetry, which almost by definition breaks most “conventional” definitions of how language behaves and how it’s structured.)
Of course, a computer can never really fully “understand” human language.
Even when the text you’re using fits the abstractions of NLP perfectly, the
results of NLP analysis are always going to be at least a little bit
inaccurate. But often even inaccurate results can be “good enough”—and in any
case, inaccurate output from NLP procedures can be an excellent source of the
sublime and absurd juxtapositions that we (as poets) are constantly in search
of.
The English Speakers Only Club
The main assumption that most NLP libraries and techniques make is that the text you want to process will be in English. Historically, most NLP research has been on English specifically; it’s only more recently that serious work has gone into applying these techniques to other languages. The examples in this chapter are all based on English texts, and the tools we’ll use are geared toward English. If you’re interested in working on NLP in other languages, here are a few starting points:
- Konlpy, natural language processing in Python for Korean
- Jieba, text segmentation and POS tagging in Python for Chinese
- The Pattern library (like TextBlob, a simplified/augmented interface to NLTK) includes POS-tagging and some morphology for Spanish in its pattern.es package.
English grammar: a crash course
The only thing I believe about English grammar is this:
“Oh yes, the sentence,” Creeley once told the critic Burton Hatlen, “that’s what we call it when we put someone in jail.”
There is no such thing as a sentence, or a phrase, or a part of speech, or even a “word”—these are all pareidolic fantasies occasioned by glints of sunlight we see on reflected on the surface of the ocean of language; fantasies that we comfort ourselves with when faced with language’s infinite and unknowable variability.
Regardless, we may find it occasionally helpful to think about language using these abstractions. The following is a gross oversimplification of both how English grammar works, and how theories of English grammar work in the context of NLP. But it should be enough to get us going!
Sentences and parts of speech
English texts can roughly be divided into “sentences.” Sentences are themselves composed of individual words, each of which has a function in expressing the meaning of the sentence. The function of a word in a sentence is called its “part of speech”—i.e., a word functions as a noun, a verb, an adjective, etc. Here’s a sentence, with words marked for their part of speech:
| I | really | love | entrees | from | the | new | cafeteria. |
| pronoun | adverb | verb | noun (plural) | preposition | determiner | adjective | noun |
Of course, the “part of speech” of a word isn’t a property of the word itself. We know this because a single “word” can function as two different parts of speech:
I love cheese.
The word “love” here is a verb. But here:
Love is a battlefield.
… it’s a noun. For this reason (and others), it’s difficult for computers to accurately determine the part of speech for a word in a sentence. (It’s difficult sometimes even for humans to do this.) But NLP procedures do their best!
Phrases
A sentence can be divided into groups of words that work as units, or “phrases.” Phrases themselves might have smaller phrases within them, forming a tree structure. Linguists traditionally draw the structure of a sentence out in an actual tree:
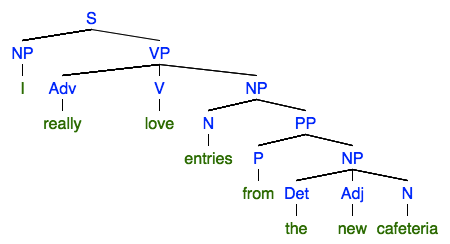
A declarative sentence consists of a noun phrase (the subject) and a verb phrase (the predicate). The verb phrase has a verb, followed (optionally, if the verb is transitive) by a noun phrase. A “noun phrase” is basically the noun, plus all of the stuff that surrounds and modifies the noun, like adjectives, relative clauses, prepositional phrases, etc. Noun phrases are handy things to be able to detect and extract, since they give us an idea of what a text might be “about.”
NLP libraries give us tools to parse sentences into trees like this, and extract phrases from the sentence according to what kind of phrase it is. Notably, TextBlob makes extracting noun phrases super easy.
But note: if computers are bad at identifying parts of speech, they’re even worse at parsing grammar in sentences. You will get some wonky results, so be prepared.
Morphology
“Morphology” is the word that linguists use to describe all of the weird ways that individual words get modified to change their meaning, usually with prefixes and suffixes. e.g.
do -> redo
sing -> singing
monarch -> monarchy
teach -> taught
A word’s “lemma” is its most “basic” form, the form without any morphology applied to it. “Sing,” “sang,” “singing,” are all different “forms” of the lemma sing. Likewise, “octopi” is the plural of “octopus”; the “lemma” of “octopi” is octopus.
“Lemmatizing” a text is the process of going through the text and replacing each word with its lemma. This is often done in an attempt to reduce a text to its most “essential” meaning, by eliminating pesky things like verb tense and noun number.
Pluralization
There’s one super important kind of morphology, and that’s the rules for taking a singular noun and turning it into a plural noun, like:
cat -> cats (easy)
cheese -> cheeses (also easy...)
knife -> knives (complicated)
child -> children (huh?)
Even though we as humans employ plural morphology in pretty much every sentence, without a second thought, the rules for how to do it are actually really weird and complicated (as with all elements of human language). A computer is never going to be able to 100% accurately make this transformation. But, again, some NLP libraries try.
Using TextBlob
At this point, let’s actually start using TextBlob so we can put this boring theory into practice.
Installation
To use textblob, we of course need to install it! And to install it, we need to create or activate a virtualenv.
$ virtualenv venv
$ source venv/bin/activate
Then, install TextBlob with pip:
$ pip install textblob
Wait as things happen. When it’s all done, you might need to download the TextBlob corpora; to do so, type the following on the command line:
$ python -m textblob.download_corpora
Sentences, words and noun phrases
Let’s play with TextBlob in the interactive interpreter. The basic steps for using TextBlob are:
- Create a TextBlob object, passing a string with the text we want to work with.
- Use various methods and attributes of the resulting object to get at various parts of the text.
For example, here’s how to get a list of sentences from a string:
>>> from textblob import TextBlob
>>> blob = TextBlob("ITP is a two-year graduate program located in the Tisch School of the Arts. Perhaps the best way to describe us is as a Center for the Recently Possible.")
>>> for sentence in blob.sentences:
... print sentence
ITP is a two-year graduate program located in the Tisch School of the Arts.
Perhaps the best way to describe us is as a Center for the Recently Possible.
The .sentences attribute of the resulting object is a list of sentences in the text. (Much easier than trying to split on punctuation, right?)
Each sentence object also has an attribute .words that has a list of words in
that sentence.
>>> from textblob import TextBlob
>>> blob = TextBlob("ITP is a two-year graduate program located in the Tisch School of the Arts. Perhaps the best way to describe us is as a Center for the Recently Possible.")
>>> for word in blob.sentences[1].words:
... print word
Perhaps
the
best
way
to
describe
us
is
as
a
Center
for
the
Recently
Possible
The TextBlob object also has a “.noun_phrases” attribute that simply returns the text of all noun phrases found in the original text:
>>> from textblob import TextBlob
>>> blob = TextBlob("ITP is a two-year graduate program located in the Tisch School of the Arts. Perhaps the best way to describe us is as a Center for the Recently Possible.")
>>> for np in blob.noun_phrases:
... print np
itp
two-year graduate program
tisch
recently
(As you can see, this isn’t terribly accurate, but we’re working with computers here. What are you going to do.)
“Tagging” parts of speech
TextBlob can also tell us what part of speech each word in a text corresponds
to. It can tell us if a word in a sentence is functioning as a noun, an
adjective, a verb, etc. In NLP, associating a word with a part of speech is
called “tagging.” Correspondingly, the attribute of the TextBlob object
we’ll use to access this information is .tags.
>>> from textblob import TextBlob
>>> blob = TextBlob("I have a lovely bunch of coconuts.")
>>> for word, pos in blob.tags:
... print word, pos
I PRP
have VBP
a DT
lovely JJ
bunch NN
of IN
coconuts NNS
This for loop is a little weird, because it has two temporary loop
variables instead of one. (The underlying reason for this is that .tags
evaluates to a list of two-item tuples, which we can automatically unpack
by specifying two items in the for loop. Don’t worry about this if it doesn’t
make sense. Just know that when we’re using the .tags attribute, you need
two loop variables instead of one.) The first variable, which we’ve called
word here, contains the word; the second variable, called pos here,
contains the part of speech.
Here’s a brief list of what the tags mean. You can see a more complete list of POS tag meanings here.
- NN: noun
- JJ: adjective
- IN: preposition
- VB_: verb (the
_gets replaced with various letters depending on the form of the verb)
Pluralization
The TextBlob library comes with a built-in kind of object called Word. If
you create a Word object, you can use its .pluralize() method to get the
plural form of that word:
>>> from textblob import Word
>>> w = Word("university")
>>> print w.pluralize()
universities
Word objects also have a .lemmatize() method, which returns the word, but with all morphology (suffixes, etc.) removed.
>>> from textblob import Word
>>> w = Word("running")
>>> print w.lemmatize()
running
All items in the .words and .tags attribute of a sentence are also secretly
Word objects, so you can call the .pluralize() method on those items when
(e.g.) looping through a list:
>>> from textblob import TextBlob
>>> blob = TextBlob("I spy a lion, a tiger, and a bear.")
>>> sentence = blob.sentences[0]
>>> for word, pos in sentence.tags:
... if pos == 'NN':
... print word.pluralize()
spies
lions
tigers
Some examples
Print only short sentences
This example takes an arbitrary input text and parses it into sentences. It then prints out ten random sentences from the text that have five or fewer words.
from textblob import TextBlob
import random
import sys
# stdin's read() method just reads in all of standard input as a string;
# use the decode method to convert to ascii (textblob prefers ascii)
text = sys.stdin.read().decode('ascii', errors="replace")
blob = TextBlob(text)
short_sentences = list()
for sentence in blob.sentences:
if len(sentence.words) <= 5:
short_sentences.append(sentence.replace("\n", " "))
for item in random.sample(short_sentences, 10):
print item
Here’s what it looks like when using Pride and Prejudice as input:
$ python hemingwayize.py < austen.txt "No, not at all." "Oh! "Ten thousand pounds! . said Frank Churchill. impossible!" 'Lord!' But the effort was painful. But what shall I say? Let Wickham be _your_ man.
Dealing with Unicode errors
Wait, what’s all that decode('ascii', errors="replace") business there?
It turns out that TextBlob is really finicky about text: if it gets anything
except plain ASCII text, it has a propensity to return strange errors. The
decode method can be called on any string; you can use it to remove any
non-ASCII characters from a string, making it safe for TextBlob. Use replace
to replace non-ASCII characters with a placeholder, or ignore to remove them
entirely. For example:
>>> string_with_stuff = "weird \xe1ccents"
>>> print string_with_stuff.decode('ascii', errors="ignore")
weird ccents
Turn any text into a list of instructions
This program extracts all noun phrases from a text, and all verbs; it then randomly selects from these lists to generate dada instructions from the text.
from textblob import TextBlob
import sys
import random
text = sys.stdin.read().decode('ascii', errors="replace")
blob = TextBlob(text)
noun_phrases = blob.noun_phrases
verbs = list()
for word, tag in blob.tags:
if tag == 'VB':
verbs.append(word.lemmatize())
for i in range(1, 11):
print "Step " + str(i) + ". " + random.choice(verbs).title() + " " + \
random.choice(noun_phrases)
Using some H. P. Lovecraft as input:
$ python instructify.py < lovecraft.txt Step 1. Sail thick forests Step 2. Come new yearnings Step 3. Lessen long grass Step 4. Buy books men Step 5. Come kuranes Step 6. Prove new name Step 7. Exist ship Step 8. Sail celephais Step 9. Remember white summit Step 10. Be old world
Create a “summary” of a text
This program “summarizes” a text in a very basic way. It does so by examining the part of speech of each word, and appending the word to a list if the word is a noun; it then prints out five random nouns from the text in plural form.
from textblob import TextBlob, Word
import sys
import random
text = sys.stdin.read().decode('ascii', errors="ignore")
blob = TextBlob(text)
nouns = list()
for word, tag in blob.tags:
if tag == 'NN':
nouns.append(word.lemmatize())
print "This text is about..."
for item in random.sample(nouns, 5):
word = Word(item)
print word.pluralize()
Using Lovecraft as input, once again:
$ python summarize_nouns.py < lovecraft.txt This text is about... men worlds seas flows autumns
Wordnet
TextBlob also provides an interface to WordNet data. WordNet is basically a computer-readable thesaurus. You can use it online here.
Wordnet’s most basic unit is the synset. A synset is essentially a “group” of different words that all mean the “same” thing. For example, wordnet might group “kitty,” “cat,” “feline,” etc. into a synset, categorized under the abstract concept of CAT.
You can get a list of synsets that wordnet thinks a word belongs to like so:
>>> from textblob import Word
>>> bank = Word("bank")
>>> synsets = bank.synsets
>>> print synsets
[Synset('bank.n.01'), Synset('depository_financial_institution.n.01'), Synset('bank.n.03'), Synset('bank.n.04'), Synset('bank.n.05'), Synset('bank.n.06'), Synset('bank.n.07'), Synset('savings_bank.n.02'), Synset('bank.n.09'), Synset('bank.n.10'), Synset('bank.v.01'), Synset('bank.v.02'), Synset('bank.v.03'), Synset('bank.v.04'), Synset('bank.v.05'), Synset('deposit.v.02'), Synset('bank.v.07'), Synset('trust.v.01')]
As you can see, the word “bank” belongs to many different synsets! We can print out WordNet’s definition for a synset like so:
>>> from textblob import Word
>>> synsets = Word("bank").synsets
>>> for synset in synsets:
... print synset.definition()
sloping land (especially the slope beside a body of water)
a financial institution that accepts deposits and channels the money into lending activities
a long ridge or pile
an arrangement of similar objects in a row or in tiers
a supply or stock held in reserve for future use (especially in emergencies)
the funds held by a gambling house or the dealer in some gambling games
a slope in the turn of a road or track; the outside is higher than the inside in order to reduce the effects of centrifugal force
a container (usually with a slot in the top) for keeping money at home
a building in which the business of banking transacted
a flight maneuver; aircraft tips laterally about its longitudinal axis (especially in turning)
tip laterally
enclose with a bank
do business with a bank or keep an account at a bank
act as the banker in a game or in gambling
be in the banking business
put into a bank account
cover with ashes so to control the rate of burning
have confidence or faith in
You can restrict which synsets to retrieve for a word for that word only when used as a particular part of speech (say noun or verb).
>>> from textblob import Word
>>> from textblob.wordnet import NOUN
>>> synsets = Word("bank").get_synsets(pos=NOUN)
>>> for synset in synsets:
... print synset.definition()
sloping land (especially the slope beside a body of water)
a financial institution that accepts deposits and channels the money into lending activities
a long ridge or pile
an arrangement of similar objects in a row or in tiers
a supply or stock held in reserve for future use (especially in emergencies)
the funds held by a gambling house or the dealer in some gambling games
a slope in the turn of a road or track; the outside is higher than the inside in order to reduce the effects of centrifugal force
a container (usually with a slot in the top) for keeping money at home
a building in which the business of banking transacted
a flight maneuver; aircraft tips laterally about its longitudinal axis (especially in turning)
We can also take any synset and use its .lemma_names() method to get all of
the words belonging to the synset, essentially giving us a list of synonyms
(words that mean the same thing). Let’s find synonyms for “bank” in the sense
of “financial institutions” (element 1 from the list above):
>>> from textblob import Word
>>> from textblob.wordnet import NOUN
>>> synsets = Word("bank").get_synsets(pos=NOUN)
>>> print synsets[1].lemma_names()
[u'depository_financial_institution', u'bank', u'banking_concern', u'banking_company']
Thanks, WordNet!
Example: Synonymize
This program reads in a ext, parses it into words, and then replaces each word with a random synonym (according to WordNet). Only words with three or more letters that have synonyms in WordNet are replaced.
from textblob import Word
import sys
import random
for line in sys.stdin:
line = line.strip()
line = line.decode('ascii', errors="replace")
words = line.split(" ")
output = list()
for word_str in words:
word_obj = Word(word_str)
if len(word_str) > 3 and len(word_obj.synsets) > 0:
random_synset = random.choice(word_obj.synsets)
random_lemma = random.choice(random_synset.lemma_names)
output.append(random_lemma.replace('_', ' '))
else:
output.append(word_str)
print " ".join(output)
$ python synonymize.py < sea_rose.txt Rose, harsh rose, scarred and with stretch of petals, meager flower, thin, spare of leaf, more wanted than a wet climb up single on a stem -- you are catch in the drift. Stunted, with minuscule leaf, you are fling on the sand, you are lift in the sharp sand that drive in the wind. Can the spice-rose drop such acid fragrancy harden in a leaf?
Further reading
TK